MCP Sampling — Let MCP Server to Use LLMs

This article is part of a 6-part series. To check out the other articles, see:
Primitives: Tools | Resources | Prompts | Sampling | Roots | Elicitation
Imagine an LLM-based fraud-detection MCP server / agent that spots an odd cluster of transactions and computes a precise risk score and a list of suspicious account IDs 📈
An MCP server typically doesn’t directly access an LLM. Instead, it presents the LLM with a catalog of its capabilities and performs operations within the six distinct primitives we defined in our "Primitives" article series. It never takes an API key to connect directly to an LLM provider — doing so would risk leaking the key.
But what if the server needs an LLM for certain tasks? Since it’s already serving an LLM client, the logical solution is to ask that client to handle the LLM interaction. This is the approach Anthropic adopted in their design.
Those numeric outputs are perfect for the detector, but useless to the compliance officer who needs a clear, human-readable justification to decide whether to freeze accounts. Sampling bridges that gap: the MCP server packages a concise, context-rich request (the scores, the relevant metadata, and a short instruction) and asks the host app’s central LLM (probably, your Cursor, VS Code, Thinkbuddy or Claude) to turn it into plain English recommendations, not like a CSV file hard to follow (maybe converted into Markdown table for most important parts)
The client shows a brief approval dialog so a human can confirm what gets sent, the LLM drafts a clear explanation and suggested next steps, the user reviews and signs off, and the server receives an auditable, user-approved narrative it can act on. This keeps computation where it belongs (specialized servers), language and governance centralized (the host LLM and the user), and avoids the cost, fragmentation, and compliance risks of giving every service its own generative model.
In Part I we’ll see why every specialized system eventually needs plain-language help and how Sampling turns that need into a safe, human-approved exchange. Part II unpacks the single JSON-RPC call—sampling/createMessage—that lets a server ask the host’s LLM for exactly the words it needs. Part III hands you drop-in code that wires this pattern into real workflows, from summarizing logs to drafting compliance reports. Part IV wraps up with the production checklist—approval UIs, fallback paths, and audit trails—so you can deploy without surprises.
Specification Note: This guide is based on the official & latest MCP Sampling specification (Protocol Revision: 2025-06-18). Where this guide extends beyond the official spec with patterns or recommendations, it is clearly marked.
Part I: Foundation - The "Why & What"
This section establishes the conceptual foundation. If a reader only reads this part, they will understand what Sampling is, why it's critically important, and where it fits in the ecosystem.
1. Core Concept
1.1 One-Sentence Definition
Sampling is a server-controlled MCP primitive that creates a division of cognitive labor, allowing a specialized server to delegate high-level reasoning, summarization, or generation tasks to the host application's more powerful, general-purpose Large Language Model under strict human governance.
1.2 The Core Analogy
The core analogy for Sampling is the "Calculator and the Writer."
- The Calculator (Your Specialized MCP Server): Imagine a brilliant mathematician who can perform incredibly complex calculations in seconds. This is your specialized server—a fraud detection engine, a clinical data processor, or a flight safety monitor. It is quantitatively powerful, accurate, and an expert in its narrow domain. However, this mathematician is a terrible communicator; their notes are just raw numbers and cryptic formulas.
- The Writer (The Host's Central LLM): Now imagine a professional speechwriter or author. They excel at understanding context, crafting persuasive narratives, and translating complex ideas into clear, accessible language for any audience. This is your host application's central LLM (e.g., Claude 3.5 Sonnet, GPT-4o).
- Sampling (The Bridge): Sampling is the formal process by which the Calculator can hand their complex results to the Writer and say, "I've done the math. Can you please explain these findings to the CEO, draft a compliant report for the regulators, and write a reassuring notification for our customers?"
This division of labor ensures each component does what it does best, transforming raw, robotic data into governed, actionable intelligence.
1.3 Architectural Position & Control Model
Sampling introduces a unique "reverse-flow" pattern within the standard MCP architecture. While most primitives involve the Client telling the Server what to do, Sampling allows the Server to make a request back to the Client/Host.
+---------------------------+ (Normal Flow: Tools, Resources) +--------------------------+
| HOST / CLIENT | ------------------------------------------> | SERVER |
| (Manages Central LLM ✍️) | (Client sends requests) | (Specialized Calculator 🧠) |
| | | |
| | <----------------------------------------- | |
| | (Sampling Flow: Server sends request) | |
+---------------------------+ sampling/createMessage +--------------------------+
Control Model: Server-Controlled
This is the most critical aspect of Sampling. The Server initiates the request for cognitive work. This is fundamentally different from Tools, which are Model-controlled. The server, after completing its specialized task, determines that it has a "Reasoning Gap" and requires the host's LLM to proceed. This request is then presented to the human user for approval via the Host application, making the entire workflow ultimately Human-Governed.
1.4 What It Is NOT
- It is NOT a way for the server to control the host's LLM. The server can only request a cognitive task; the host (and the user) has ultimate authority to approve, deny, or modify that request.
- It is NOT just another remote procedure call (RPC). The dual-checkpoint governance model and the delegation of cognitive work (reasoning, generation) rather than just deterministic computation make it a unique architectural pattern for building trustworthy AI systems.
2. The Problem It Solves
2.1 The LLM-Era Catastrophe
Sampling was designed to prevent three catastrophic architectural failure modes that emerge when enterprises deploy specialized AI systems at scale:
- The Reasoning Gap: Specialized systems are brilliant at computation but terrible at communication. This creates a bottleneck where servers detect critical issues with superhuman accuracy, but the output is robotic jargon that humans cannot act on quickly. This leads to costly interpretation delays, compliance failures when reports are incomprehensible, and customer confusion.
- The Efficiency Problem (Architectural Bloat): The default solution to the Reasoning Gap is to embed an LLM inside every specialized server. At an enterprise scale with dozens of systems, this leads to an explosion in costs, immense developer overhead for maintaining numerous separate LLM integrations, and severe vendor lock-in.
- The Governance Breakdown: When specialized systems are equipped with their own LLMs, they often operate without human oversight. This can lead to an AI making unauthorized commitments, sending inappropriate communications, or submitting flawed regulatory filings—creating massive financial and legal liabilities.
2.2 Why Traditional Approaches Fail
The common workaround is to build a custom, brittle integration for every server that needs generative capabilities. This approach fails spectacularly at scale:
- Unsustainable Costs: Maintaining dozens of independent LLM instances is prohibitively expensive, with each instance incurring significant API and maintenance costs.
- Inconsistent Quality: Each server ends up with a different LLM, leading to a fragmented user experience and inconsistent quality in generated content across the organization.
- No Central Governance: It becomes impossible to enforce a universal standard for AI-generated content, creating a minefield of compliance and brand reputation risks. Each team reinvents the wheel for security and oversight, often poorly.
Sampling replaces this chaos with a single, elegant, and secure architectural pattern.
Part II: Technical Architecture - The "How"
3. Protocol Specification
3.1 Request & Response Schemas
Sampling is implemented via the sampling/createMessage method.
Request: sampling/createMessage
A server sends this request to the client to ask the host's LLM to perform a generative task.
{
"jsonrpc": "2.0",
"method": "sampling/createMessage",
"params": {
"messages": [
{
"role": "user",
// The content for the LLM to process. This is an OBJECT, not an array.
"content": {
"type": "text",
"text": "Summarize these findings..."
}
}
],
// Provides guidance to the client on which model to select.
"modelPreferences": {
// (0.0-1.0) How important are advanced capabilities? Higher values prefer more capable models.
"intelligencePriority": 0.9,
// (0.0-1.0) How important is low latency? Higher values prefer faster models.
"speedPriority": 0.3,
// (0.0-1.0) How important is minimizing costs? Higher values prefer cheaper models.
"costPriority": 0.5,
// Advisory list of preferred model names or families, as an array of objects.
"hints": [
{ "name": "claude-3.5-sonnet" },
{ "name": "sonnet" }
]
},
// Optional system prompt to guide the LLM's behavior.
"systemPrompt": "You are a helpful medical compliance assistant.",
// A top-level parameter to limit the generation length.
"maxTokens": 2048
},
"id": "sampling-req-001"
}
Successful Response
If the request is approved by the user and processed by the LLM, the client returns the generated content.
{
"jsonrpc": "2.0",
"id": "sampling-req-001",
"result": {
// The role of the message's author, always "assistant" for a response.
"role": "assistant",
// The generated content, as a single OBJECT.
"content": {
"type": "text",
"text": "Here is a summary of the findings..."
},
// The name of the model that was actually used.
"model": "claude-3.5-sonnet-20240620",
// Reason generation stopped.
"stopReason": "endTurn"
}
}
stopReasonValues Explained:"endTurn": The model completed its response naturally."maxTokens": Generation stopped because it reached themaxTokenslimit."stopSequence": Generation stopped because it encountered a user-defined stop sequence (a common implementation extension).
3.2 Model Hints Mapping Strategy
The modelPreferences.hints array allows a server to suggest preferred models without creating a hard dependency. Clients treat these hints as advisory and may map them to equivalent models if the requested one is unavailable. For instance, if a server sends a hint for "claude-3-sonnet" but the client only has access to Google models, it might intelligently map this hint to "gemini-1.5-pro" based on similar capabilities. This ensures interoperability across a diverse AI ecosystem.
3.3 Multi-Modal Content Types
The content object is not limited to text. The protocol supports multi-modal interactions.
Image Content:
{
"type": "image",
"data": "base64-encoded-image-data",
"mimeType": "image/jpeg"
}
Audio Content:
{
"type": "audio",
"data": "base64-encoded-audio-data",
"mimeType": "audio/wav"
}
3.4 Common Implementation Extensions
While the official specification is minimal, many real-world implementations add parameters for more granular control.
Note: The following parameter is a common implementation pattern but is not part of the official MCP specification.
includeContext(String): Specifies how much conversational history to include. Common values are"none","thisServer", or"allServers".
4. The Lifecycle & Message Flow
The Sampling lifecycle is designed for maximum safety, with two mandatory human-in-the-loop review stages.
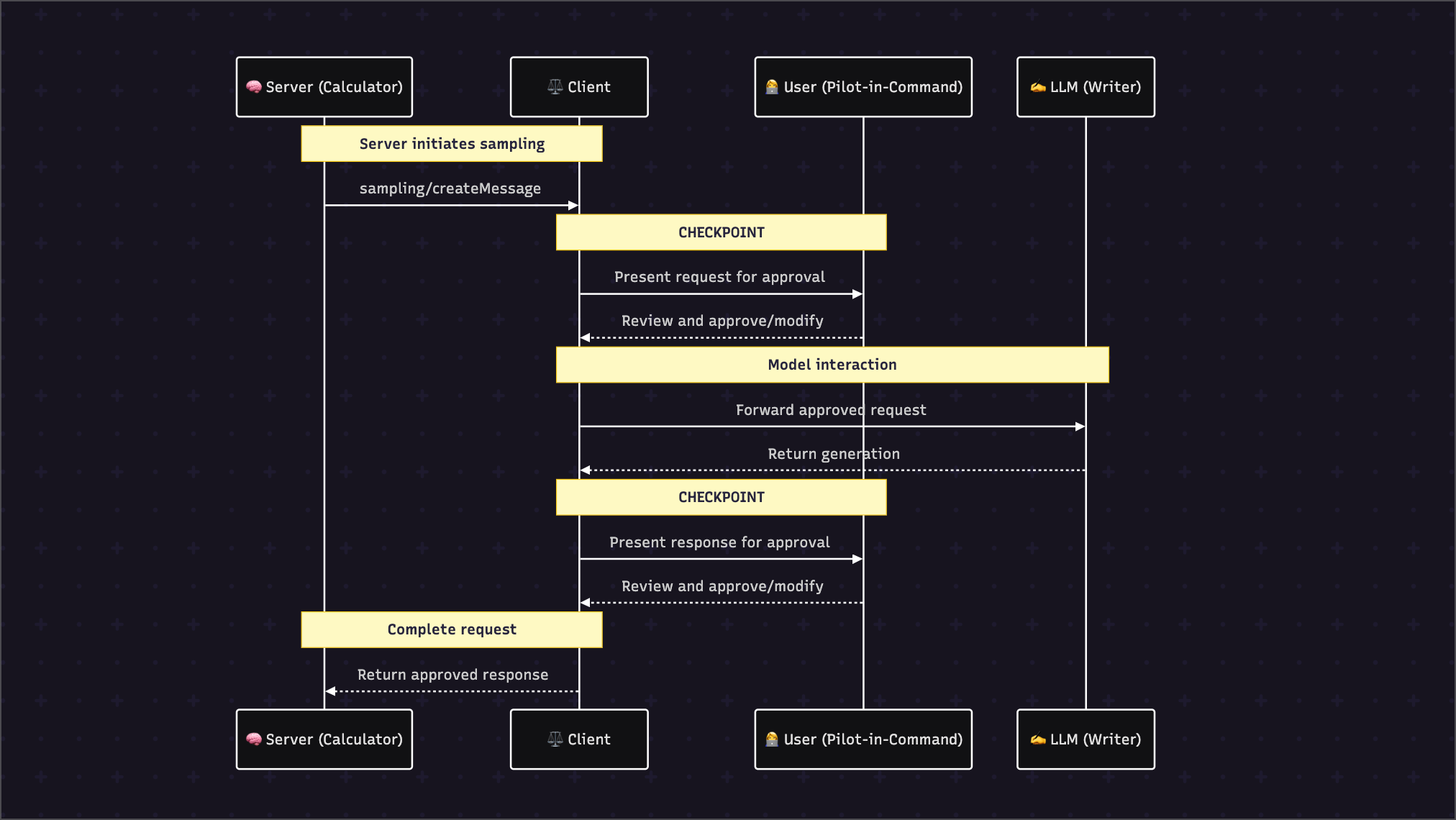
Part III: Implementation Patterns - The "Show Me"
5. Pattern 1: The Canonical "Golden Path"
- Goal: To perform a simple summarization task, demonstrating the core end-to-end flow of Sampling.
- Key Takeaway: The server's logic is simple: it packages a request and
awaits a response. All the complexity of the dual-checkpoint UI, LLM invocation, and security is handled abstractly by the MCP client and themcp.context.sample()call.
Implementation (Python/FastMCP):Server-Side (summarize_server.py)
This server exposes a single Tool that takes text, and instead of summarizing it locally, it uses Sampling to delegate the task to the host's LLM.
# server.py
import asyncio
from fastmcp import FastMCP, tool, Message, TextContent
mcp = FastMCP("summarizer", "1.0.0")
@tool()
async def summarize_text(text_to_summarize: str) -> str:
"""
Summarizes the provided text using the host's advanced LLM.
"""
print(f"Server: Received text. Requesting summarization from host LLM...")
# Construct the Sampling request
try:
# CHECKPOINT #1 starts here. The client will show a UI.
completion = await mcp.context.sample(
messages=[
Message(
role="user",
# The content is a single object, not a list.
content=TextContent(text=f"Please provide a concise, one-paragraph summary of the following text:\n\n{text_to_summarize}")
)
],
# Note: The FastMCP SDK automatically converts Python's snake_case arguments
# (e.g., model_preferences) to the protocol's camelCase (modelPreferences).
model_preferences={"intelligencePriority": 0.8, "costPriority": 0.9},
max_tokens=150
)
# CHECKPOINT #2 is handled by the client before this call returns.
if completion.content and isinstance(completion.content, TextContent):
summary = completion.content.text
print(f"Server: Received summary from host: '{summary[:50]}...'")
return summary
else:
return "Error: Host returned an empty or invalid response."
except Exception as e:
print(f"Server: Sampling request failed or was rejected: {e}")
return "Summarization was cancelled by the user."
if __name__ == "__main__":
asyncio.run(mcp.start())
6. Pattern 2: The Compositional Workflow
- Goal: To demonstrate the powerful "Compute-and-Interpret" pattern, where a
Toolperforms a quantitative calculation andSamplingprovides a qualitative interpretation. - Key Takeaway: This pattern perfectly embodies the "division of cognitive labor." The
Toolprimitive handles the deterministic, computational part of the task, while theSamplingprimitive handles the nuanced, generative part.
Implementation (Python/FastMCP): A financial server has a tool to calculate portfolio risk. The tool computes a numeric score, then uses Sampling to explain what that score means.
# finance_server.py
import asyncio
from fastmcp import FastMCP, tool, Message, TextContent
mcp = FastMCP("risk-analyzer", "1.0.0")
def _calculate_risk_score(volatility: float, diversification: float) -> float:
return (volatility * 1.5) / (diversification + 0.1)
@tool()
async def get_portfolio_risk_analysis(volatility: float, diversification: float) -> str:
"""
Calculates a portfolio risk score and provides a human-readable interpretation.
"""
risk_score = _calculate_risk_score(volatility, diversification)
print(f"Server: Calculated risk score: {risk_score:.2f}")
prompt = (
f"A portfolio risk analysis returned a score of {risk_score:.2f} (where >5 is high risk). "
"Please write a brief, one-sentence interpretation of this score for a financial advisor."
)
try:
completion = await mcp.context.sample(
messages=[Message(role="user", content=TextContent(text=prompt))],
model_preferences={"intelligencePriority": 0.9},
max_tokens=100,
system_prompt="You are a financial risk analyst assistant."
)
interpretation = "No interpretation available."
if completion.content and isinstance(completion.content, TextContent):
interpretation = completion.content.text
return f"Risk Score: {risk_score:.2f}\nInterpretation: {interpretation}"
except Exception as e:
print(f"Server: Interpretation failed: {e}")
return f"Risk Score: {risk_score:.2f}\nInterpretation: Could not be generated (request denied)."
7. Pattern 3: The Domain-Specific Solution (Healthcare/HIPAA)
- Goal: To process sensitive patient data to identify a high-risk medication interaction and generate a HIPAA-compliant alert, complete with an audit trail.
- Key Takeaway: Sampling is a compliance-enabling architecture. The dual-checkpoint lifecycle provides a framework for auditable human consent, and the compact payload pattern helps enforce data minimization principles like HIPAA's "minimum necessary" rule.
Implementation: This server runs as a background process monitoring data. When it finds something, it proactively uses Sampling.
# hipaa_monitor_server.py
import asyncio
import json
import logging
from datetime import datetime, timezone
from fastmcp import FastMCP, Message, TextContent
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(message)s')
mcp = FastMCP("clinical-monitor", "1.0.0")
def log_hipaa_event(event_type: str, details: dict):
log_entry = {
"timestamp_utc": datetime.now(timezone.utc).isoformat(),
"event_type": event_type, "server_id": "clinical-monitor", **details
}
logging.info(json.dumps(log_entry))
async def monitor_patient_data():
""" Main monitoring loop. """
while True:
interaction_data = {
"patient_id_hashed": "a1b2c3d4...", "medication_A": "Warfarin",
"medication_B": "Amiodarone", "risk_level": "CRITICAL",
"finding_id": "finding-xyz-789"
}
log_hipaa_event("RISK_DETECTED", interaction_data)
prompt = (
"A critical medication interaction has been detected. "
f"Patient ID (Hashed): {interaction_data['patient_id_hashed']}. "
"Draft a concise, urgent alert for the attending physician. "
"DO NOT include any PII other than the provided hashed ID."
)
try:
# Per the Official Spec: Clients SHOULD implement user approval controls.
# ⚠️ SECURITY CRITICAL: The host MUST ensure the approver has the correct credentials.
log_hipaa_event("SAMPLING_REQUESTED", {"finding_id": interaction_data['finding_id']})
# Assume approver_id is securely obtained from the host context.
approver_id = "dr_chen_456"
completion = await mcp.context.sample(
messages=[Message(role="user", content=TextContent(text=prompt))],
model_preferences={"intelligencePriority": 1.0, "hints": [{"name": "claude-4-medical"}]},
max_tokens=150
)
if completion.content and isinstance(completion.content, TextContent):
physician_alert = completion.content.text
print(f"Generated Alert: {physician_alert}")
log_hipaa_event("ALERT_GENERATED_AND_APPROVED", {
"finding_id": interaction_data['finding_id'],
"approver_id": approver_id,
"alert_content_hash": hash(physician_alert)
})
except Exception as e:
log_hipaa_event("SAMPLING_REJECTED", {"finding_id": interaction_data['finding_id'], "approver_id": approver_id, "reason": str(e)})
await asyncio.sleep(60)
@mcp.on_start
async def start_monitoring():
asyncio.create_task(monitor_patient_data())
if __name__ == "__main__":
asyncio.run(mcp.start())
Part IV: Production Guide - The "Build & Deploy"
8. Server-Side Implementation
8.1 Core Logic & Handlers
A production server's core responsibility is to construct valid sampling/createMessage requests and gracefully handle both success and failure.
Per the Official MCP Specification:
"For trust & safety and security, there SHOULD always be a human in the loop with the ability to deny sampling requests."
This means your server logic MUST anticipate and handle rejection as a normal operational path.
8.2 Production Hardening
- Security: Input & Content Validation
Per the spec, servers SHOULD validate message content. Sanitize all inputs used to construct prompts to prevent injection attacks. - Observability: Structured Logging
Log every sampling request and its outcome. This is vital for debugging, auditing, and monitoring costs.
Security: Fallback Logic
The most critical security feature is handling user rejection. Your server must have a fallback path.
# Fallback pattern inside a tool
try:
completion = await mcp.context.sample(...)
return completion.content.text
except Exception:
# If sampling fails or is denied, return the raw data instead.
return f"Raw Data (Interpretation unavailable): {raw_data}"
9. Client-Side Implementation
9.1 Core Logic: Capability Declaration
A client that supports Sampling MUST declare this capability during the initialize handshake. Failure to do so will result in servers being unable to use the feature.
// Client's 'initialize' request params
{
"protocolVersion": "1.0",
"clientInfo": { "name": "MyAIApp", "version": "2.0.0" },
"capabilities": {
// This object signals to all connected servers that this client
// can handle 'sampling/createMessage' requests.
"sampling": {}
}
}
9.2 User Experience (UX) Patterns for Governance
The dual-checkpoint UI is not optional; it is the core of Sampling's security model. A compliant client MUST implement these patterns.
Checkpoint #1: The Request Approval UI
When a sampling/createMessage request is received, the client must display a modal dialog with:
- Clear Attribution: "The 'Clinical Analysis Server' wants to..."
- Clear Intent: "...generate an FDA report."
- Data Preview: A safe, summarized preview of the data being sent to the LLM.
- Clear Action Buttons:
[ Approve ][ Modify Prompt ][ Deny ]
Checkpoint #2: The Response Approval UI
After the LLM returns content, the client must display a second dialog:
- Context: "Response for the 'Clinical Analysis Server'."
- Generated Content Preview: Show the full generated text for review.
- Clear Action Buttons:
[ Approve & Send ][ Discard ]
Part V: Guardrails & Reality Check - The "Don't Fail"
10. Decision Framework
10.1 When to Use This Primitive
| If you need to... | Then use Sampling because... | An alternative would be... |
|---|---|---|
| Translate complex, quantitative data into natural language. | It provides a secure, governed bridge to a powerful LLM, separating calculation from communication. | Embedding a full LLM in your server, which is expensive and hard to maintain. |
| Centralize AI costs and governance across many specialized systems. | It allows dozens of "calculator" servers to share one central "writer" LLM, creating massive cost and operational efficiencies. | Building and maintaining N×M custom integrations, which is architecturally unsustainable. |
| Enforce auditable, human-in-the-loop workflows for AI actions. | Its dual-checkpoint lifecycle is designed specifically for compliance, ensuring no AI content is used without explicit human review. | Building a custom approval workflow from scratch, which is complex and error-prone. |
10.2 Critical Anti-Patterns (The "BAD vs. GOOD")
- The "Rubber Stamp Factory"
This occurs when the human approval process becomes so fast and reflexive that it provides no real oversight.- BAD (Process): A UI that encourages users to click "Approve" without reading, or client logic that auto-approves requests. This violates the spirit and safety requirements of the protocol.
- GOOD (Process): Implement risk-based approval flows. High-risk requests should require a second confirmation step (like typing "confirm") to force conscious consideration.
- The "Silver Bullet" Syndrome
This is the mistaken belief that Sampling's LLM can solve problems without sufficient context from the server. - Disabling Graceful Degradation
This is when a server is architected to fail completely if a sampling request is denied.
GOOD (Code):
# The server has a planned fallback path.
try:
completion = await mcp.context.sample(...)
return completion.content.text
except Exception:
return "Interpretation denied by user. Returning raw data: [raw_data_json]"
BAD (Code):
# No try/except block. If sample() fails, the whole tool call crashes.
completion = await mcp.context.sample(...)
return completion.content.text
GOOD (Code):
# Server provides a compact, context-rich payload.
prompt = "Analyze financial risk indicators: volatility=0.8, correlation=-0.2..."
await mcp.context.sample(messages=[Message(role="user", content=TextContent(text=prompt))])
BAD (Code):
# Server sends a vague request with no context.
await mcp.context.sample(messages=[Message(role="user", content=TextContent(text="Analyze."))])
11. The Trust Model: Enforced vs. Cooperative
Understanding the division of responsibility is critical for secure implementation.
| Aspect | Spec Requirement | Protocol Enforcement (MCP Guarantees) | Developer Responsibility (YOU Must Implement) |
|---|---|---|---|
| Human Approval | SHOULD | None. The protocol defines the message, but does not render the UI. | ⚠️ CRITICAL. The client developer MUST implement the dual-checkpoint UI. If they don't, the entire security model fails. |
| Server-to-LLM Communication | N/A | Enforced. A server can NEVER call the host's LLM API directly. It can only send a sampling/createMessage request. |
Cooperative. The server developer must write correct fallback logic for when the request is denied. |
| Rate Limiting | SHOULD | None. The protocol does not enforce rate limits. | Cooperative. The client developer is responsible for implementing rate limits to prevent server abuse. |
| Handle Sensitive Data | MUST | None. The protocol transports whatever data is given to it. | Cooperative. Both server and client developers MUST ensure PII and other sensitive data are handled according to compliance rules (e.g., minimization, redaction). |
Part VI: Quick Reference - The "Cheat Sheet"
12. Common Operations & Snippets
Server-Side: Requesting a Summary (Python/FastMCP)
try:
completion = await mcp.context.sample(
messages=[Message(role="user", content=TextContent(text="Summarize..."))],
model_preferences={"intelligencePriority": 0.8},
max_tokens=200
)
summary = completion.content.text
except Exception as e:
summary = f"Summarization failed: {e}"
13. Configuration & Error Code Tables
Official sampling/createMessage Parameters
| Parameter | Type | Required | Description |
|---|---|---|---|
messages |
Array | Yes | An array of message objects for the LLM to process. |
modelPreferences |
Object | No | Priorities and hints to guide the client's model selection. |
systemPrompt |
String | No | A system prompt to guide the LLM's persona and behavior. |
maxTokens |
Integer | No | The maximum number of tokens to generate. |
Common Implementation Extensions (Not in Official Spec)
| Parameter | Type | Description |
|---|---|---|
includeContext |
String | Controls how much conversational history to include ("none", "thisServer"). |
temperature |
Float | Controls randomness in the output (0.0-1.0). |
stopSequences |
Array | An array of strings that will stop generation when encountered. |
Error Code Reference
| Code | Meaning | Recommended Action |
|---|---|---|
-1 |
User rejected request | Server: Execute graceful fallback logic. Do not retry. |
-32601 |
Method not found | Server: The client doesn't support Sampling. Log and disable the feature. |
-32602 |
Invalid Params | Server: The request was malformed. Log the error and fix the implementation. |
| Impl-Specific | Rate Limit Exceeded | Server: Wait and retry with exponential backoff. |
| Impl-Specific | Model Unavailable | Server: Retry later or fall back to a different modelPreferences hint. |